AI VIDEO BRIEFING
Redis란 무엇인가: 단일 스레드 실행, 인메모리 저장, 자료구조 서버의 작동 원리
Redis는 단일 스레드로 명령을 하나씩 처리하는 인메모리 자료구조 서버다. 파이프라이닝으로 지연을 숨기고, 캐시·복제본·RDB 스냅샷·AOF로 내구성을 조절하며, 복제본과 클라이언트 측 샤딩으로 확장한다. 캐싱·속도 제한·정렬 순위표 같은 실제 활용까지 정리했다.
핵심 메시지
쉽게 이해하기
Redis는 단일 스레드 방식의 인메모리 자료구조 서버다. 이 짧은 설명에는 세 가지 중요한 설계 선택이 담겨 있다. 첫째는 단일 스레드 실행이다. Redis는 하나의 스레드에서 명령을 한 번에 하나씩 처리하므로 순서가 예측 가능하고, 같은 키에 대한 동시 쓰기나 잠금을 고민할 필요가 없다. 대신 한 명령이 막히면 뒤의 모든 명령이 대기한다. 엄밀히는 Redis 6 이상에서 네트워킹용 IO 스레드가 추가됐지만, 실제 명령 로직은 여전히 순차적으로 실행된다.
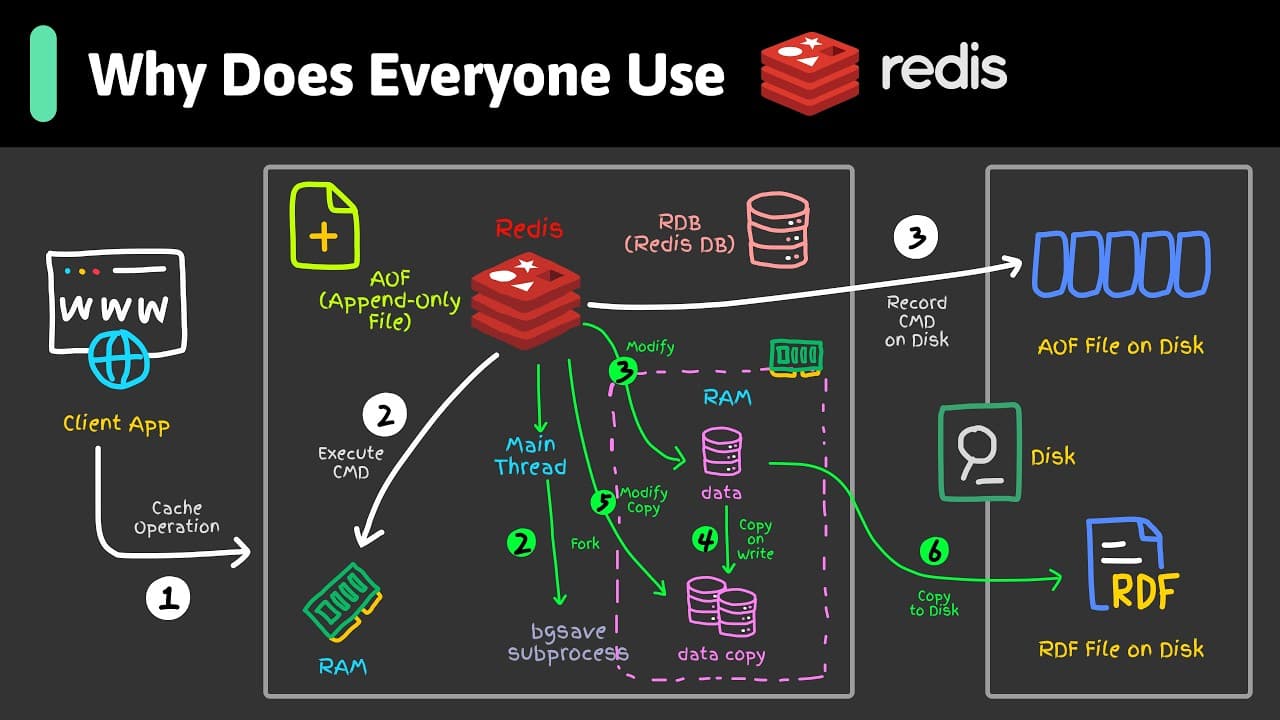
스레드를 하나만 쓰면서도 빠른 비결은 배치 처리다. 클라이언트는 파이프라이닝과 트랜잭션으로 여러 명령을 묶어 한 번의 네트워크 왕복으로 전달할 수 있다. 단일 스레드가 명령을 순서대로 실행하는 것은 같지만, 소켓이 매 요청-응답을 기다리며 노는 대신 계속 사용되어 지연 시간이 가려진다. 둘째 선택은 데이터를 RAM에 저장하는 것이다. 덕분에 초당 수백 개의 명령에도 1밀리초 미만으로 응답하지만, 기기가 고장 나면 영속성을 신중히 설정하지 않는 한 메모리의 데이터는 사라진다.
셋째 선택은 자료구조를 직접 노출하는 키-값 저장소라는 점이다. 값은 문자열, 리스트, 해시, 셋, 정렬 집합, 스트림 등 다양한 형태가 될 수 있고, 각 구조마다 특화된 명령이 있다. 예를 들어 카운터를 5로 설정한 뒤 증가 명령을 쓰면 원자적으로 6이 된다. 여러 클라이언트가 같은 키를 건드릴 때 이 원자성이 중요한데, Redis가 명령을 한 번에 하나씩 실행하므로 증가 작업이 단일 단계로 끝나 서로 간섭하지 않는다.
메모리에 데이터를 두는 만큼 내구성 전략은 팀마다 다르다. 많은 팀은 영속성을 끄고 Redis를 순수 캐시로 쓴다. 진실의 원천은 데이터베이스이고 Redis는 캐시 결과만 저장하므로, Redis가 충돌해도 애플리케이션이 DB에서 다시 생성하면 된다. 일부는 복제본을 추가해 주 노드가 쓰기를, 복제본이 읽기를 맡고 장애 시 복제본이 대신하게 한다(복제본은 메모리 사용량을 대략 두 배로 늘린다). RDB 스냅샷을 켜면 몇 분마다 스냅샷을 떠 재시작 시 따뜻한 데이터로 응답하되 마지막 스냅샷 이후의 쓰기는 잃는다. 잃으면 안 되는 데이터라면 AOF를 켜는데, 모든 쓰기를 로그에 추가하고 보통 초당 한 번 fsync하므로 장애 시 최대 1초 분량만 손실된다. 결국 핵심 질문은 이 저장소가 중요한 상태를 지켜야 하는지, 단순 캐시인지다.
확장은 대개 단일 인스턴스로 시작한다. 읽기가 병목이면 복제본을 더해 읽기 트래픽을 분산하지만 쓰기 처리량은 여전히 기본 서버가 감당한다. 처리량이 한 인스턴스로 부족해지면 클라이언트 측 샤딩을 도입해 키를 해시하고 그 값으로 여러 독립 인스턴스에 나눈다. 정적 클러스터에는 단순 모듈러 해시가, 동적 확장에는 ketama 같은 일관된 해싱이 어울린다. 자동 샤딩과 장애 조치가 필요하면 Redis 클러스터를 쓰지만 운영·디버깅 복잡성이 늘어, 많은 팀은 캐시 워크로드에는 단순한 클라이언트 측 샤딩을 선호한다. 대표 활용은 캐싱(DB 앞에서 결과 저장, TTL이나 LRU 제거 정책으로 정리), 원자적 증가 명령을 이용한 속도 제한, 그리고 정렬 집합을 이용한 순위표·인기 목록이다.
주요 인사이트
- 단일 스레드 실행 덕분에 같은 키에 대한 동시 쓰기나 잠금을 고민할 필요가 없고 명령 순서가 예측 가능하다. 대신 한 명령이 막히면 뒤의 모든 명령이 대기한다.
- INCR 같은 명령이 원자적으로 한 단계에 끝나기 때문에 여러 클라이언트가 같은 카운터를 동시에 올려도 서로 간섭하지 않는다.
- 내구성 설정은 결국 '이 데이터가 사라져도 되는가'라는 질문으로 귀결된다. 순수 캐시라면 영속성을 꺼도 되고, 잃으면 안 되는 데이터라면 AOF를 켠다.
- 확장은 한꺼번에 클러스터로 가기보다 복제본과 클라이언트 측 샤딩으로 단순하게 시작하고, 꼭 필요할 때만 클러스터를 도입하는 편이 운영이 쉽다.
- 정렬 집합(sorted set)은 관계형 데이터베이스로 구현하기 번거로운 순위표·인기 목록 문제를 자연스럽게 해결해 준다.
자주 묻는 질문
Redis는 단일 스레드인데 어떻게 빠른가요?
명령 로직은 단일 스레드에서 순서대로 실행하지만, 파이프라이닝과 트랜잭션으로 여러 명령을 한 번의 네트워크 왕복에 묶어 보냅니다. 덕분에 소켓이 매 요청-응답을 기다리며 노는 대신 계속 사용되어 지연 시간이 가려지고, 데이터가 메모리에 있어 응답이 1밀리초 미만으로 빠릅니다. Redis 6 이상은 네트워킹용 IO 스레드를 추가했지만 명령 실행은 여전히 순차적입니다.
Redis의 데이터는 서버가 죽으면 사라지나요?
기본적으로 메모리에 저장되므로 영속성을 설정하지 않으면 충돌 시 사라집니다. 팀에 따라 영속성을 끄고 순수 캐시로 쓰거나, 복제본을 두거나, 주기적 RDB 스냅샷을 뜨거나, 모든 쓰기를 로그에 남기는 AOF를 사용합니다. AOF에 초당 fsync를 쓰면 장애 시 최대 1초 분량만 손실됩니다.
Redis는 어떻게 확장하나요?
대부분 단일 인스턴스로 시작합니다. 읽기가 병목이면 복제본을 추가해 읽기 트래픽을 분산하고, 쓰기 처리량까지 부족해지면 클라이언트 측 샤딩으로 여러 인스턴스에 키를 해시해 나눕니다. 자동 샤딩과 장애 조치가 필요하면 Redis 클러스터를 쓰지만 운영·디버깅 복잡성이 늘어납니다.
Redis는 주로 어디에 쓰이나요?
대표적으로 캐싱(데이터베이스 앞에서 결과를 저장하고 TTL이나 LRU로 정리), 원자적 증가 명령을 이용한 속도 제한(사용자·IP·토큰 단위), 그리고 정렬 집합을 이용한 순위표·인기 목록 구현에 쓰입니다.
원문과 출처
이 글은 원본 영상의 자막을 바탕으로 한국어 독자를 위해 요약했습니다. 전체 맥락과 최신 정보는 원문에서 확인하세요.
YouTube 원본 영상 보기 ↗